Beyond the Model: Hardening Your AI Workflow
Do I need a PhD to secure my neural network implementation?

Treating neural networks as untrusted modules within a standard software pipeline.
A checklist for securing your AI-integrated automation.
Beyond the Model: Hardening Your AI Workflow
When we talk about "securing neural networks," the conversation often drifts into the weeds of adversarial machine learning—theoretical attacks where someone adds a few pixels of noise to an image to trick a classifier. While fascinating for researchers, this is rarely the problem for a software engineer building an automation pipeline.
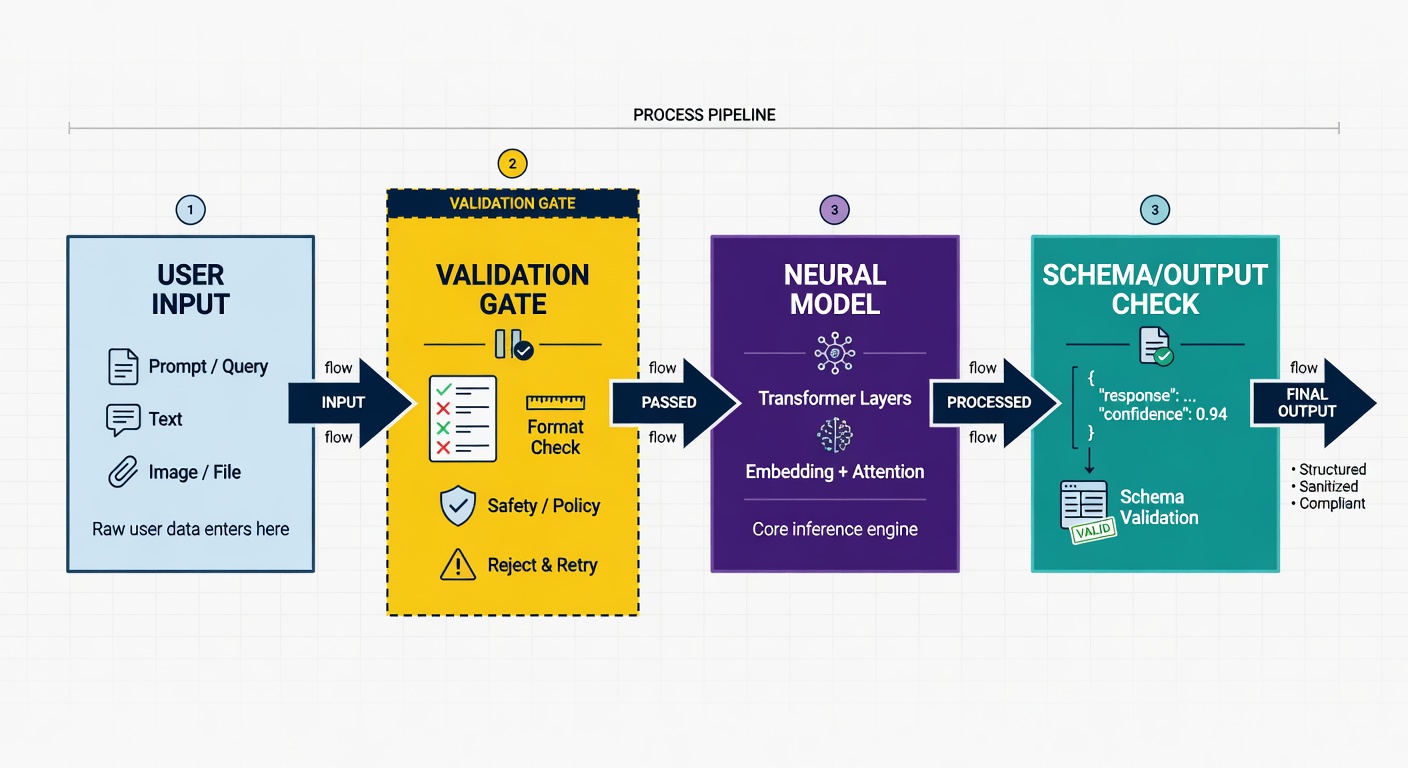
The real security threat isn't the model itself; it’s how we integrate these "black boxes" into our existing software architecture.
The problem
Most developers treat AI models as trusted services. We send user input to an API, get a response, and pass it directly to our database or UI. We’ve spent decades learning to sanitize SQL queries and escape HTML, yet when we integrate an LLM or a classification model, we suddenly treat the output as gospel.
What I noticed
In my recent automation projects, I’ve seen a recurring pattern: developers focus on optimizing the prompt or the training data, but ignore the boundary of the model. If your neural network is an untrusted module, you are effectively running a remote code execution risk every time you execute a predict() call. The OWASP Top 10 for LLMs confirms this: the primary risks are injection, insecure output handling, and sensitive data leakage—all of which are standard application security failures, not "AI" failures.
Where AI fits
AI is just another component. If you wouldn't trust a raw user string to run a bash command, why would you trust it to guide the reasoning of a model that controls your business logic? AI security isn't about protecting the weights of the model; it's about hardening the pipeline that feeds it and processes its output.
My working approach
I treat every neural network integration as a "Zero Trust" zone.
- Input Sanitization: Treat the model’s input prompt as a template. If the user controls the input, you must have a validation layer that strips away potential jailbreak attempts or malicious context injection.
- Output Validation: Never pass raw model output to a system function. If your model generates code or JSON, run it through a schema validator or a static analysis tool before it hits your production environment.
- Least Privilege: Does the model really need access to your entire database? If it's just classifying emails, give it a read-only view of a specific buffer, not the whole company directory.
Practical example: The Guardrail Layer
Instead of calling an API directly, I use a simple wrapper pattern. Here is how I think about it in Python:
# DON'T: call_model(user_input)
# DO: The Guardrail Wrapper
def secure_action(user_input):
if not input_is_safe(user_input): # Regex check or semantic filter
raise SecurityException("Invalid input detected")
raw_response = model.predict(user_input)
if not validate_schema(raw_response): # JSON schema validation
return fallback_logic()
return process(raw_response)
What I would avoid
- Over-engineering: Don't try to build a custom "adversarial detection" model unless you are at a massive scale. It’s expensive and often ineffective.
- Black-box trust: Avoid assuming the provider (OpenAI, Anthropic, or HuggingFace) is handling your security. They secure their infrastructure; you are responsible for your application logic.
- Hard-coding secrets: Never include API keys or sensitive context in the prompt template that could be exposed via prompt injection.
Try this next
- Audit your inputs: Find every place your app sends user-generated content to a neural network. Add a length constraint and a prohibited-keyword filter (a simple regex for things like "ignore previous instructions").
- Schema enforcement: If your model returns JSON, use a library like
Pydanticto enforce the structure. If the model fails to adhere to the schema, treat it as an error, not a feature. - Log and monitor: Treat "model failures" like you would a 500 error in a standard web app. Track how often your validation layer triggers.
Keep reading
Follow the thread

The Agentic Trap: Why Your AI Assistant Needs a Leash
How do I build an agent that can actually do work without accidentally leaking customer data or deleting my database?
Read this noteSame lane, different angle
The Architecture of Autonomy: Why Your Workflows Are Brittle
How do I stop fixing my bots every time a process changes?
The Cognitive Debt of AI: Why I'm Restricting My Kids' Access to 'Smart' Assistants
But there is a dangerous crossover when we apply this engineering mindset to child development.